Frequently Asked Questions (FAQ)
General
- Q: What is KonDATA?
- A: KonDATA is the institutional research data repository of the University of Konstanz. Members of the University of Konstanz can use the service to publish their research data.
- Q: Who is allowed to use data on KonDATA?
- A: Publishing data is reserved for members of the University of Konstanz. External users are also allowed to search the repository and download the data. Here, the use is not restricted to one group of people.
- Q: Why does KonDATA exist?
- A: The publication of research data as a scientific product has been increasing in recent years, leading to increased transparency of research and its results. To make the data available, there is a need for storage services called repositories. In addition to subject-specific and general repositories, institutional repositories play a role if there are no suitable subject-specific repositories for data sets or if it is important that the data remains on-site at one's own institution. KonDATA is a solution for this case.
- Q: What does data publication cost?
- A: Currently, publishing data via KonDATA is free of charge for users.
- Q: What kind of datasets can be published through KonDATA?
- A: KonDATA is open to datasets from all scientific disciplines.
- Q: Can I include data published via KonDATA in my publication list?
- A: Yes, data published via KonDATA is assigned a Digital Object Identifier (DOI). This is globally unique and does not change. You can use the DOI to include the published data in your publication list and scientists who re-use your data can cite you via the DOI.
- Q: Where can interested scientists find my published data?
- A: KonDATA provides a search function. Users can search the collection via the web interface. In addition, the metadata is exposed in the following services, making it easier to find:
Data publication
- Q: How does publishing on KonDATA work?
- A: If you want to publish data on KonDATA, the first step is a conversation with the KonDATA team. Here we will be happy to advise you on your data sets and set up your own workspace in KonDATA. You can then access the workspace independently and start submitting your data.
- You then use the KonDATA web interface to prepare your data for publication. You describe the data with so-called metadata to document it and make it understandable for interested users. Examples of metadata include the names of the people involved in the dataset, keywords that describe the content of the data, and a license under which you publish the data.
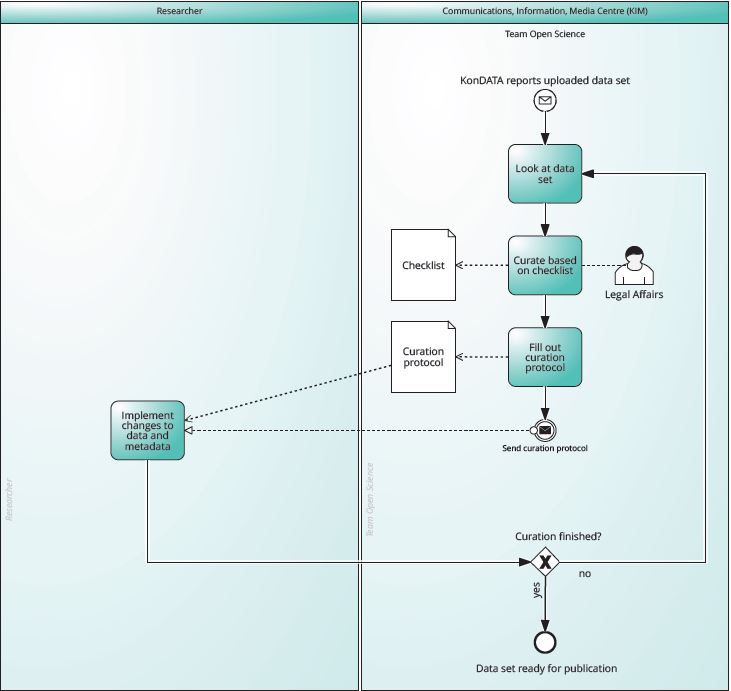
- Once you are done preparing the data, the KonDATA team performs curation (see question "How does data curation work?"). We review the research data and metadata and, if necessary, make suggestions for improvement, which we send to you in the form of a curation protocol.
- Once both parties are satisfied, the data approved for publication and are subsequently accessible via the KonDATA website.
- Q: How does the data curation work?
- A: Once you have prepared your data for publication via the KonDATA web interface, we perform a curation of the (meta) data. In doing so, we follow a checklist that helps us verify that your data files can be accessed and that the metadata fields are filled in appropriately. We record suggestions in a curation protocol, which we send to you. You can then implement the suggestions yourself in KonDATA.
- Q: What licenses are available for publishing in KonDATA?
- A: Various Creative Commons licenses are available for publication.
- Q: What formats should the data be in?
- A: If possible, you should use open formats appropriate for long-term archiving. This will increase the reusability of your data, as it will allow people who do not have access to paid software to use it.
- Q: Is there a possibility of a timed embargo?
- A: Yes, datasets in KonDATA can be embargoed. This means that the metadata and DOI of the dataset are visible online, while access to the associated research data is only possible after the specified time period has expired.
- In selected cases, a permanent embargo is also possible, e.g. for datasets containing personal information. This means that the dataset is publicly proven and discoverable without access to the research data being possible.
- Q: How large can datasets be in KonDATA?
- A: Currently there is no fixed limit regarding the total volume of a dataset. In order to simplify the handling of large data sets, they are split up in KonDATA. For this purpose, a header dataset is created which links to the respective sub-datasets. This way, users do not have to download the entire dataset to get a first impression of its content.
- When submitting such a dataset, there are a few points to keep in mind:
- The sub-package files can be combined into zip/tar archives before uploading.
- To reduce the upload time, the checksums of the individual files should be calculated locally.
- An internet conncetion with as large a bandwidth as possible should be used for the upload, otherwise timeouts and aborts may occur.
- When submitting such a dataset, there are a few points to keep in mind: